


Using Machine Learning to Improve Email Marketing Success
How do you write emails that your prospects and customers want to open, and avoid emails that sour them to your brand?
Dedicated email marketers and their multi-functional counterparts have grown familiar and adept with A/B testing thanks to user-friendly Martech and the acceptance of A/B testing as best practice. Still, email remains a battleground—one many marketers feel they’re losing. What if there was a better way?
One potentially powerful solution on the horizon is machine learning. Marketing futurists will tell you that one day, AIs leveraging deep repositories of user data will be able to write and deliver the perfect personalized email.
While we’re not there yet, today’s blog will take a first step in the right direction by showing how engineering.com is leveraging machine learning to write better email subject lines and improve campaign success, to the benefit of both its audience and customers.

This goal of this post is to provide marketers who are regularly authoring email marketing campaigns with a thorough understanding of what we’re doing, so they too can leverage this exciting tool. Because of this, the article will at times get technical. To help you better navigate the post, here’s a breakdown of what each section covers:
- How emails are improved today – A quick review of current A/B testing and email performance analysis best practices.
- The study’s methodology: How we built an email sorting algorithm to predict campaign outcomes before they go live.
- The study’s results. What we learned, including a list of words the model shows you should avoid in your email campaigns.
- How we’re operationalizing the model and where we’re going next.
How Emails are Improved Today – The Basics of A/B Testing and Regression
The process of A/B testing is a well-established principle of email marketing. For most marketers, the process works as follows:
- A marketing email is drafted
- A variable is selected to test, be it the send time, personalization, subject line, etc.
- The email client subdivides your mailing list into groups A and B (the test groups) and C the remainder of your list.
- You and your manager make a wager for lunch as to what variation will work best (this step isn’t necessary, but we enjoy it at our office and I enjoy the free lunches)
- The experiment is run with variants A & B competing against one another. After a set period of time a winner is chosen based on whichever criteria you selected (opens, clicks, etc.).
- The winning email is sent to C.
This process should look familiar to just about every marketer, and for most this is where the process ends. It’s a powerful tool, and even minimal analysis via an eye-test provides actionable insights. Still, there are marketers who take it a step further, leveraging campaign data gathered over months and years. They’ll take all that data and statistically analyze it using t-tests and logistic regression to determine not only what variables significantly impact email outcomes, but also by how much.
Email marketers with access to huge data sets have taken these types of analyses even further, and nobly shared their results to the betterment of our industry as a whole. Omnibus regression studies from the likes of Hubspot’s Tom Monaghan and Mailchimp have analyzed datasets of 1.8 and 24 billion emails respectively to generate email marketing best practices. For instance, these studies have shown convincingly that emojis, personalization and “Thank you” positively impact email campaigns, while LAST CHANCE and SIGN UP do the opposite.

These types of studies can be incredibly daunting and complex when subject lines are the target of investigation. With tens—if not hundreds of thousands—of words to test, you’re either going to need an incredible amount of time to work on this, or more likely only get to test a handful of your hypotheses about suspected high-impact words. The following methodology overcomes these limitations.
A Machine Learning Methodology for Better Email Marketing Campaigns
So how do you build a machine learning algorithm to improve email marketing? There are probably many ways, but in broad strokes I’m going to explain my methodology.
Step 1 – Cleaning the data: This is the longest and most tedious step in building our model. During this step, I removed punctuation, capitalization and emojis to make processing and analyzing the subject line text easier. I also removed campaigns that went to highly targeted and small segments of the entire list because the results for these campaigns are often much higher than baseline.
Step 2 – Standardizing outputs: Open rates vary between email lists, and within the same list over time. To account for this, I adjusted the open rate data to account for temporal changes and changes due to major events, like email list pruning. Next, I converted open rates to standard deviations from the mean so that I could compare data across the multiple lists I used for the analysis.
Step 3 – Deciding on a Model & Platform: The goal of my model was to predict how well an email would perform based solely on subject lines. Many email clients already use Naïve Bayes algorithms to filter emails, so I decided for this first attempt to use the same method for this study. You’ll also need a predictive modeling platform to run a study like this. I decided to use Rapidminer because it has a 30 day fully unlocked free trial, and received praise on the Cross Validated forums.
Step 4 – Building the Model: Building the model was easy. First, I split my dataset in two, so I would have something to train the model on and something to test it on. Next, I programmed the model to learn the relationship between how well each campaign performed and the language used in the subject lines. To analyze the text, I used a process called tokenization, which breaks apart the subject lines into individual words and then makes a big matrix from which the algorithm learns from.
Step 5 – Cross-Validation: When building a model, it’s important to make sure it works. This is where the second half of the data set came in. Testing the model against a data set with known outcomes lets us evaluate the model and generate an accuracy score. Here are the model results:
accuracy: 60.14% +/- 2.09%
| true Positive Outcome | true Negative Outcome | class precision | |
| pred. Positive Outcome | 834 | 808 | 50.79% |
| pred. Negative Outcome | 232 | 735 | 76.01% |
| class recall | 78.24% | 47.63% |
Interpreting the Results
There are two measures of relevance for any model: precision and recall. Simply put, precision is how well your model performed, and recall in the sensitivity of your model. As we’re interested in predicting outcomes, I’m going to focus on precision.
Our model’s precision was 60.14%, meaning that given a subject line the model would correctly predict it as being a strong performer or poor performer that often. It was far less precise at accurately predicting winning emails, with only 50.79% of its predictions being correct, but was much better at correctly categorizing underperforming emails at a clip of 76.01%.
We should not interpret these results too harshly. The model is using only one, albeit very important, variable in the email open equation. Subject lines are critical to email success or failure, but so too is the frequency of emails sent from your list, your list/sender authority and the campaign’s degree of segmentation, not to mention the day and times you send your emails. A future model incorporating that information as well would likely be much more accurate and thus much more useful.
However, back to these results. I’m not certain yet why the model isn’t able to predict winning emails, but I have two hypotheses, neither of which should surprise marketers. First, people are much more certain of what they don’t like. Certain words, as we’ll show next, can strongly dissuade people from taking action, but there are fewer words that will consistently prompt them to take action. Secondly, successful emails may be more influenced by the factors we mentioned in the previous paragraph than the subject line itself. Thinking of my own experience, an email from a client or my boss will definitely get opened regardless of what the subject line is, whereas an email inquiry about a partnership may or may not depending on other factors.
While the positive outcome identification was disappointing, I’m quite excited about the model’s ability to predict negative outcomes. Knowing we have a great email campaign would be nice, but avoiding a bad email campaign is, in my opinion, much more valuable.
Unsuccessful campaigns can cost you dearly, as the below graph from Tom Monaghan’s presentation from Inbound 2016 shows. Bad campaigns annoy your subscribers, reduce engagement—or worse, earn you an unsubscribe or spam report. Worse still, the department or client on whose behalf you’re sending the email will be much more vocal about a poor performing campaign than they will be praiseful of a successful campaign. By first assessing a potential campaign using this model, you’d be able to reduce the number of underperforming campaigns you send by nearly 50%.
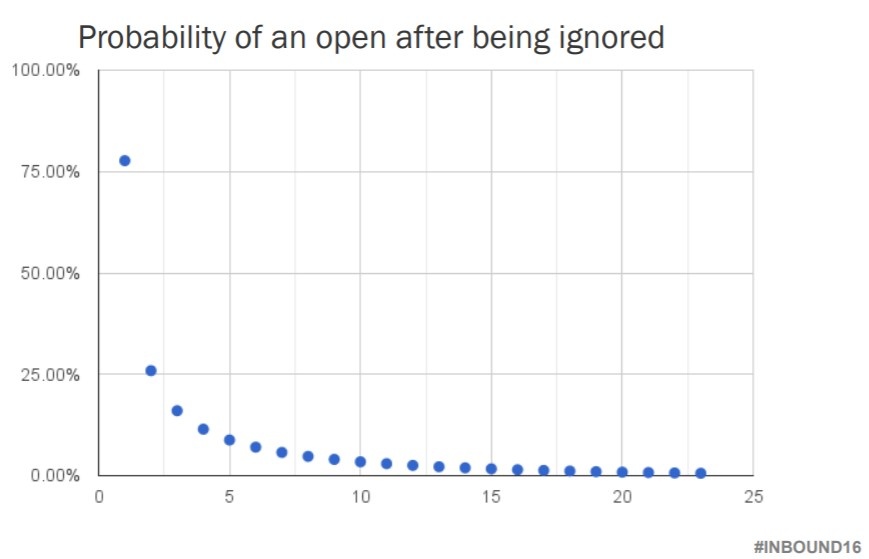 (courtesy of Tom Monaghan’s Inbound16 presentation)
(courtesy of Tom Monaghan’s Inbound16 presentation)
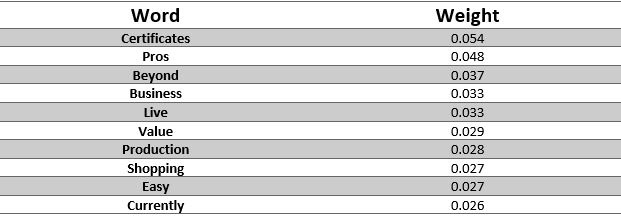
Here are some of the most common words the model suggests you avoid using if you want to improve your email:
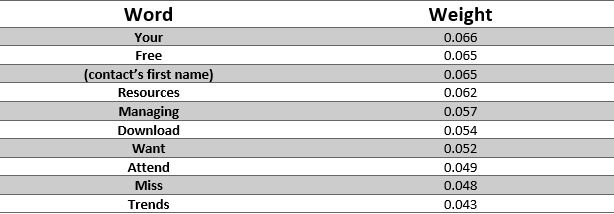
For reference, while not as precise, here are some of the words more strongly correlated with positive outcomes:
Next Steps & Operationalizing Machine Learning for Email Marketing
Improving the model will require a few things. Firstly, more data. This model considered just over 2,600 email marketing campaigns engineering.com executed over the last little while. Compared to the Mailchimp study mentioned at the start of this article, we’re working with 0.000042% of the data. More data will allow us to really peel down further and introduce a lot more granularity around certain words, and hopefully improve the model’s ability to identify positive outcomes.
The model will likely massively benefit by including the influential non-subject line data discussed in the interpretation section. Days of the week and time sent are two variables all marketers can easily and often experiment with, so adding that to the analysis would be a good starting point. Sender relationship and degree of targeting are much more abstract, but are likely very important, so I will endeavour to account for them in the future.
As for operationalizing, if this was true machine learning it would be the machine writing the subject lines and tweaking subsequent ones based on what it learns. I don’t know about you, but I’m not willing to relinquish that degree of control just yet. That being said, we will take the “words to avoid” into consideration when writing future email subject lines. We’ll also have the model predict campaign outcomes before they’re pushed out, to weed out campaigns with a high probability to underperform.
I hope you found this article informative. If you’d like to know more, or discuss email open rates and machine learning, feel free to leave a comment below or reach out to me on LinkedIn or via email.
Thanks for reading,
Andrew


Leave a Comment
You must be logged in to post a comment.